SpeechKit Brand Voice Adaptive от Яндекса
Бета
Яндекс поддерживает синтез речи с переменными на базе технологии Yandex SpeechKit Brand Voice Adaptive.
Возможность интеграции с Yandex SpeechKit Brand Voice Adaptive через JAICP находится в раннем доступе. Оставьте заявку на адрес client@just-ai.com для получения подробной информации.
Использование
Чтобы использовать технологию в проектах на JAICP, необходимы следующие действия.
- Подготовка входных данных. Подготовьте корпус шаблонов и записей диктора для обучения модели. Следуйте всем требованиям, предъявляемым к качеству данных. Данные будут переданы в Яндекс.
-
Подготовка модели синтеза. Яндекс обучает модель. Цикл обучения занимает порядка календарного месяца.
-
Размещение модели синтеза. Яндекс размещает обученную модель в Yandex.Cloud и выдает ID модели, который можно использовать в проекте.
-
Настройка синтеза в JAICP. В параметрах телефонного канала заполните настройки синтеза. В качестве голоса укажите полученный ID модели:
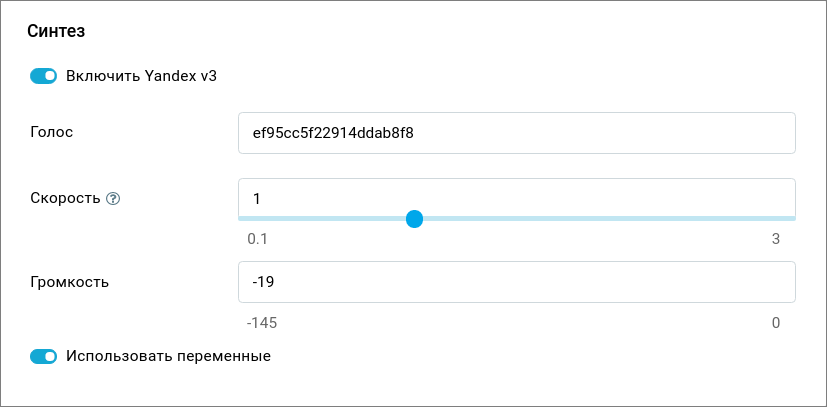
Далее вы можете использовать в сценарии синтез речи с переменными для генерации ответов бота.
Для этого вам потребуется метод $reactions.ttsWithVariables.
Мы также готовы предоставить собственные модели синтеза для дообучения на ваших данных — так подготовительный этап пройдет гораздо быстрее.
Ограничения
Ограничение на длину фраз
Длина фраз, которые подаются на синтез речи с переменными, не должна превышать:
- 24 секунды озвученного текста;
- 250 символов, включая пробелы и знаки препинания.
Иначе провайдер вернет ошибку.
Ограничение на код сценария
При использовании синтеза речи с переменными в сценарии не работает тег a и метод $reactions.answer.
Помимо вызова $reactions.ttsWithVariables возможно только воспроизведение аудио через тег audio или $reactions.audio.
Повторное обучение
При синтезе возможно использовать шаблоны, которые не участвовали в обучении модели. Однако качество вставки переменных в такие шаблоны не гарантируется.